Air Quality Dataset#
In this section, we detail the pytorch code for designing an explainable deep model for processing the Air Quality dataset.
Air Quality (AirQ) is a dataset for forecasting with time-series inputs.
Please download the dataset here and update the tutorial data path accordingly.
This hourly data set contains the PM2.5 data (target) of the US Embassy in Beijing. Meanwhile, meteorological data (inputs channels) from Beijing Capital International Airport are also included. The time period is between Jan 1st, 2010 to Dec 31st, 2014.
We will predict the "PM2.5" value over a horizon using a lookback with different channels: "PM2.5", and the other sensor values.
The following image summarizes the dataset.
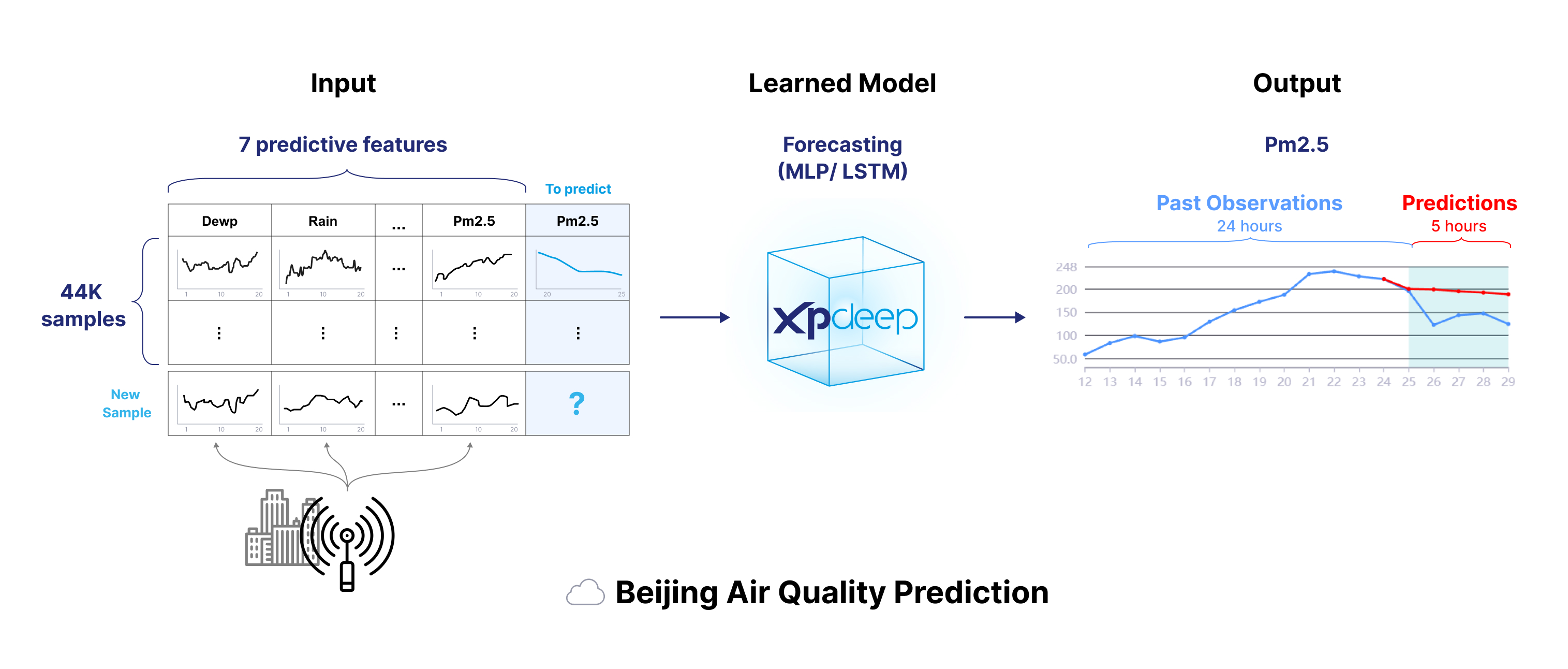
Please follow this end-to-end tutorial to prepare the dataset, create and train the model, and finally compute explanations.
Prepare the Dataset#
1. Split and Convert your Raw Data#
The first step consists in creating your train, test and validation splits as StandardDataset.
As we only have a single data file, we will use 60% of the data to make a train split, 10% for the test split and 10% for the validation split.
Let's transform the data:
import pandas as pd
from datetime import datetime, timezone
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({'pm2.5': data['pm2.5'].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=timezone.utc), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True)
data.drop(columns=['cbwd'], inplace=True)
# Set the "time" column as index
data = data.set_index("time")
data.head()
pm2.5 DEWP TEMP PRES Iws Is Ir
time
2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 1.79 0 0
2010-01-02 01:00:00 148.0 -15 -4.0 1020.0 2.68 0 0
2010-01-02 02:00:00 159.0 -11 -5.0 1021.0 3.57 0 0
2010-01-02 03:00:00 181.0 -7 -5.0 1022.0 5.36 1 0
2010-01-02 04:00:00 138.0 -7 -5.0 1022.0 6.25 2 0
We need now to compute the target "pm2.5" and the features "sensor airquality" from the current columns. Currently, each sample represents sensor values for a specific timestamp. We will convert the data to a format where each sample is a set of time serie channels, each representing a sensor value.
After the transformation, we need to split a sample into a lookback (input timestamps) and a horizon
(timestamps to predict). We chose a lookback of 24, and a horizon of 5, to split the original 48 timestamps.
For that process, we overlap each samples: timestamp 1 to 25 represent the 1st sample, timestamp 2 to 26 the 2nd, etc.
import torch
import numpy as np
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well (with its lookback we predict the horizon)
data_target_numpy = data[['pm2.5']].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(1, 1, *repeated_data_input.shape[2:])
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(1, 1, *repeated_data_target.shape[2:])
# Reshape the input and target data
transformed_inputs = torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
transformed_targets = torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist()
})
We can now split the train data into a train and validation set.
from sklearn.model_selection import train_test_split
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
Warning
A few samples will overlap between train, test, and val as we split the whole generated array into train, test and validation splits.
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
As stated in the doc, Xpdeep requires a ".parquet" file to create the dataset.
Tip
To get your ".parquet" files, you can easily convert each split from pandas.DataFrame to pyarrow.Table first.
Like pandas.DataFrame, pyarrow.Table does not support multidimensional arrays, please ensure to convert
arrays to lists first.
Warning
Here with set preserve_index to False in order to remove the DataFrame "index" column from the resulting Pyarrow Table.
import pyarrow as pa
import pyarrow.parquet as pq
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
2. Upload your Converted Data#
Warning
Don't forget to set up a Project and initialize the API with your credentials !
from xpdeep import init, set_project
from xpdeep.project import Project
init(api_key="api_key", api_url="api_url")
set_project(Project.create_or_get(name="AirQ Tutorial"))
With your Project set up, you can upload the converted parquet files into your fsspec compatible storage, here an S3 bucket.
import boto3
from botocore.client import Config
client = boto3.client(
service_name="s3",
endpoint_url=S3_DATASET_ENDPOINT_URL,
aws_access_key_id=S3_DATASET_ACCESS_KEY_ID,
aws_secret_access_key=S3_DATASET_SECRET_ACCESS_KEY,
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", S3_DATASET_BUCKET_NAME, "air_quality/train.parquet")
client.upload_file("val.parquet", S3_DATASET_BUCKET_NAME, "air_quality/val.parquet")
client.upload_file("test.parquet", S3_DATASET_BUCKET_NAME, "air_quality/test.parquet")
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
3. Find a schema#
For AirQ, we cannot use the AutoAnalyzer
as it does not support time serie features yet. We need therefore to create either an
AnalyzedSchema
or FittedSchema,
from scratch. We will scale the channels,
therefore we can create directly a FittedSchema because our preprocessors don't require a fitting step.
We add a time serie feature (7 channels, asynchronous), and a univariate asynchronous time serie feature for the target (the pm2.5 channel).
We use the custom preprocessor class Scaler that inherit from TorchPreprocessor, and allow us to use torch.Tensor
to scale time series. All we need is to implement transform and ìnverse_transform methods in the child class, as it done in the following code snippet.
Info
Here, as the FittedSchema is built from scratch and not from an AnalyzedParquetDataset.fit method, please add the
input_size and target_size parameters, required to serialize the models that will use the schema associated data.
Remember to add a 1 as batch dimension, which is the first element of the provided sizes here.
import torch
from xpdeep.dataset.preprocessor.preprocessor import TorchPreprocessor
class Scaler(TorchPreprocessor):
def __init__(self, input_size: tuple[int, ...], mean: torch.Tensor, scale: torch.Tensor):
super().__init__(input_size=input_size)
# Saved as buffer for torch.export: saved loaded with `state_dict` but not optimized with `optimizer.step()
self.register_buffer("mean", mean)
self.register_buffer("scale", scale)
def transform(self, inputs: torch.Tensor) -> torch.Tensor:
"""Transform."""
return (inputs - self.mean) / self.scale
def inverse_transform(self, output: torch.Tensor) -> torch.Tensor:
"""Apply inverse transform."""
return output * self.scale + self.mean
As you can see, we used two attributes: scale and mean. These attributes are not present by default in
TorchPreprocessor,
but can be added as keyword arguments when instantiating Scaler.
Let's now define the FittedSchema. We use Scaler to define the preprocessors.
import torch
from xpdeep.dataset.schema import FittedSchema
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
UnivariateTimeSeriesFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
+---------------------------------------------------------------+
| Schema Contents |
+-------------------------------+-------------------+-----------+
| Type | Name | Is Target |
+-------------------------------+-------------------+-----------+
| MultivariateTimeSeriesFeature | sensor airquality | ❌ |
| UnivariateTimeSeriesFeature | target pm2.5 | ✅ |
| IndexMetadata | airq_index | |
+-------------------------------+-------------------+-----------+
Note
Please note that the __airq_index__ column is set as a IndexMetadata in the Schema.
Finally, we can create the FittedParquetDataset corresponding to the train split.
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_dataset",
path=f"s3://{S3_DATASET_BUCKET_NAME}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema
)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
Tip
Here we did not build a ParquetDataset
first as we create the dataset straight from the existing fitted schema.
The ParquetDataset
interface serves only as an intermediate class, used to obtain an AnalyzedParquetDataset
via the AutoAnalyzer and its analyze method.
We use the same FittedSchema to create a FittedParquetDataset corresponding to the validation and test set.
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_dataset",
path=f"s3://{S3_DATASET_BUCKET_NAME}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_dataset",
path=f"s3://{S3_DATASET_BUCKET_NAME}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema
)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
And that's all for the dataset preparation. We now have three FittedParquetDataset, each with its FittedSchema, ready to be used.
Prepare the Model#
We need now to create an explainable model XpdeepModel.
1. Create the required torch models#
We have a forecasting task with time serie input data. We will use a
Multi Layer Perceptron (MLP) for this task, without BackboneModel.
Tip
Model input and output sizes (including the batch dimension) can be easily retrieved from the fitted schema.
Therefore, we chose:
- The
FeatureExtractionModelthat will embed input data. - The
TaskLearnerModelthat will return an output of size 5. - We won't use
BackboneModel.
import torch
from torch.nn import Sequential
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
2. Explainable Model Specifications#
Here comes the crucial part: we need to specify model specifications under ModelDecisionGraphParameters to get the best explanations (Model Decision Graph and Inference Graph).
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
For further details, see docs
Note
All parameters have a default value, you can start by using those default value, then iterate and update the configuration to find suitable explanations.
3. Create the Explainable Model#
Given the model architecture and configuration, we can finally instantiate the explainable model XpdeepModel.
from xpdeep.model.xpdeep_model import XpdeepModel
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
Train#
The train step is straightforward: we need to specify the Trainer parameters.
from functools import partial
import torch
from torch.optim.lr_scheduler import ReduceLROnPlateau
from xpdeep.metric import DictMetrics, TorchLeafMetric, TorchGlobalMetric
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from torchmetrics import MeanSquaredError
from xpdeep.trainer.trainer import Trainer
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
Note
We use TorchGlobalMetric and TorchLeafMetric to encapsulate the metrics. They give us more flexibility, for instance here we compute metrics on the raw data and not on the preprocessed data, as it easier to interprete an MSE on the un-normalized bike count. Find more information here.
Warning
Here, we set foreach and fused to False as currently it may leads to unstable behaviour in the training process.
We can now train the model:
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
The training logs are displayed in the console:
Epoch 1/20 - Loss: 0.977: 1%| | 3/274 [00:00<00:32, 8.25it/s]
Epoch 1/20 - Loss: 0.776: 3%|▎ | 7/274 [00:00<00:28, 9.28it/s]
Epoch 1/20 - Loss: 0.574: 4%|▍ | 11/274 [00:01<00:26, 9.93it/s]
Epoch 1/20 - Loss: 0.618: 6%|▌ | 16/274 [00:01<00:26, 9.74it/s]
Epoch 1/20 - Loss: 0.570: 7%|▋ | 19/274 [00:02<00:26, 9.71it/s]
Once the model trained, it can be used to get explanations.
Explain#
Similarly to the Trainer, explanations are computed with an Explainer interface.
1. Build the Explainer#
We provide the Explainer quality metrics to get insights on the explanation quality. In addition, we compute along with the explanations histograms to get a detailed distribution on targets and predictions (horizon) as well as on the inputs (lookback).
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(metric=partial(MeanSquaredError, num_outputs=5),
on_raw_data=True,
reduced_dimensions=[0, 2])
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
Tip
Here we add a custom metric, the per-timestamp MSE which allows us to visualize the per timestamp MSE averaged over
all channels with XpViz.
2. Model Functioning Explanations#
Model Functioning Explanations are computed with the global_explain method.
model_explanations = explainer.global_explain(trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(model_explanations.visualisation_link)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
We can visualize explanations with XpViz, using the link in model_explanations.visualisation_link, if you already
have requested the correct credentials.
3. Inference and their Causal Explanations#
We need a subset of samples to compute Causal Explanations on. Here we filter the test set to take only the first 100 samples.
from xpdeep.filtering.filter import Filter
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
Future Release
Time serie filters will be implemented to filter based on channel values.
Explanation can then be computed using the local_explain method from the Explainer.
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
👀 Full file preview
"""Air quality workflow, forecasting with time series data."""
import os
from datetime import UTC, datetime
from functools import partial
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import MultivariateTimeSeriesFeature, UnivariateTimeSeriesFeature
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import FittedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(4)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Remove the first rows (incorrect values for some columns) .
data = pd.read_csv("air_quality.csv")[24:]
# Fill NA/NaN values by propagating the last valid observation to next valid value.
data.update({"pm2.5": data["pm2.5"].ffill()})
# Convert time to python datetime.
data["time"] = data.apply(
lambda x: datetime(year=x["year"], month=x["month"], day=x["day"], hour=x["hour"], tzinfo=UTC), axis=1
)
# Remove unnecessary columns.
data.drop(columns=["year", "month", "day", "hour", "No"], inplace=True) # noqa: PD002
data.drop(columns=["cbwd"], inplace=True) # noqa: PD002
# Set the "time" column as index
data = data.set_index("time")
data.head()
# Create the samples
lookback = 24
horizon = 5
# Calculate the number of samples based on dataset length, look_back, and horizon. Each sample overlap the
# next by 1 timestamp.
num_samples = len(data) - lookback - horizon + 1
data_input_numpy = data.to_numpy() # Inputs contains the target channel as well
# (with its lookback we predict the horizon)
data_target_numpy = data[["pm2.5"]].to_numpy()
# Broadcast the data input and target
repeated_data_input = np.broadcast_to(data_input_numpy, (num_samples, *data_input_numpy.shape))
repeated_data_target = np.broadcast_to(data_target_numpy, (num_samples, *data_target_numpy.shape))
# Generate tensor slices with overlap
tensor_slices = torch.arange(lookback + horizon).unsqueeze(0) + torch.arange(num_samples).unsqueeze(1)
# Get the input and target slices
input_slices = tensor_slices[:, :lookback]
target_slices = tensor_slices[:, lookback:]
time_dimension = 1
# Number of dimensions apart from the temporal one (for multivariate, it's 1)
number_of_data_dims = len(data.shape) - 1
# Gather input and target data using the slices
input_indices_to_gather = input_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_input.shape[2:]
)
target_indices_to_gather = target_slices.unsqueeze(*list(range(-number_of_data_dims, 0))).repeat(
1, 1, *repeated_data_target.shape[2:]
)
# Reshape the input and target data
transformed_inputs = (
torch.gather(torch.from_numpy(repeated_data_input), time_dimension, input_indices_to_gather).numpy().copy()
)
transformed_targets = (
torch.gather(torch.from_numpy(repeated_data_target), time_dimension, target_indices_to_gather).numpy().copy()
)
data = pd.DataFrame({
"sensor airquality": transformed_inputs.tolist(), # Convert to a list of arrays for storage in DataFrame
"target pm2.5": transformed_targets.tolist(),
})
# Split the data into training and validation sets
train_data, test_val_data = train_test_split(data, test_size=0.2, random_state=42)
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="airq_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="airq_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="airq_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "air_quality/test.parquet")
input_tensor = torch.tensor(data["sensor airquality"].to_list())
mean_input = input_tensor[:, 0, :].mean(dim=0)
scale_input = input_tensor[:, 0, :].std(dim=0)
target_tensor = torch.tensor(data["target pm2.5"].to_list())
mean_target = target_tensor[:, 0, :].mean(dim=0)
scale_target = target_tensor[:, 0, :].std(dim=0)
# 3. Find a schema
fitted_schema = FittedSchema(
ExplainableFeature(
name="sensor airquality",
preprocessor=Scaler((24, 7), mean=mean_input, scale=scale_input),
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True, channel_names=["pm2.5", "DEWP", "TEMP", "PRES", "Iws", "Is", "Ir"]
),
),
ExplainableFeature(
name="target pm2.5",
preprocessor=Scaler((5, 1), mean=mean_target, scale=scale_target),
is_target=True,
feature_type=UnivariateTimeSeriesFeature(
asynchronous=True,
channel=("sensor airquality", "pm2.5"),
),
),
IndexMetadata(name="airq_index"),
input_size=(1, 24, 7),
target_size=(1, 5, 1),
)
print(fitted_schema)
fit_train_dataset = FittedParquetDataset(
name="air_quality_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/train.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fitted_schema,
)
fit_test_dataset = FittedParquetDataset(
name="air_quality_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="air_quality_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/air_quality/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1:]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(7, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.reshape(-1, 7, lookback)
return super().forward(x)
class TaskLearner(Sequential):
def __init__(self):
layers = [torch.nn.Flatten(), torch.nn.LazyLinear(out_features=horizon)]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = super().forward(inputs)
return x.reshape(-1, horizon, 1)
feature_extractor = FeatureExtractor()
task_learner = TaskLearner()
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_flatten_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [
EarlyStopping(monitoring_metric="mse", mode="minimize", patience=5),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=3, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.01, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=torch.nn.MSELoss(reduction="none"), model=xpdeep_model, fitted_schema=fit_train_dataset.fitted_schema
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=30,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
histogram_input=HistogramStat(
on="input", num_bins=20, num_items=1000, feature_name="sensor airquality", on_raw_data=True
),
)
# Here we add a per-time stamp mse (num_outputs is the number of timestamps)
leaf_metric_per_timestamp_mse = TorchLeafMetric(
metric=partial(MeanSquaredError, num_outputs=5), on_raw_data=True, reduced_dimensions=[0, 2]
)
metrics.update({"leaf_metric_per_timestamp_mse": leaf_metric_per_timestamp_mse})
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="AirQ Tutorial"))
try:
main()
finally:
get_project().delete()
We can again visualize causal explanations using the visualisation_link.