Har Dataset#
In this section, we detail the pytorch code for designing an explainable deep model for processing the Human Activity Recognition dataset.
Human Activity Recognition (HAR) is a dataset for classification with time-series inputs.
Please download and unzip the dataset as a zip here and update the tutorial data path accordingly.
HAR has been collected from 30 subjects performing six different activities (Walking, Walking Upstairs, Walking Downstairs, Sitting, Standing, Laying). It consists in inertial sensor data that was collected with a smartphone carried by the subjects.
The following image summarizes the dataset.
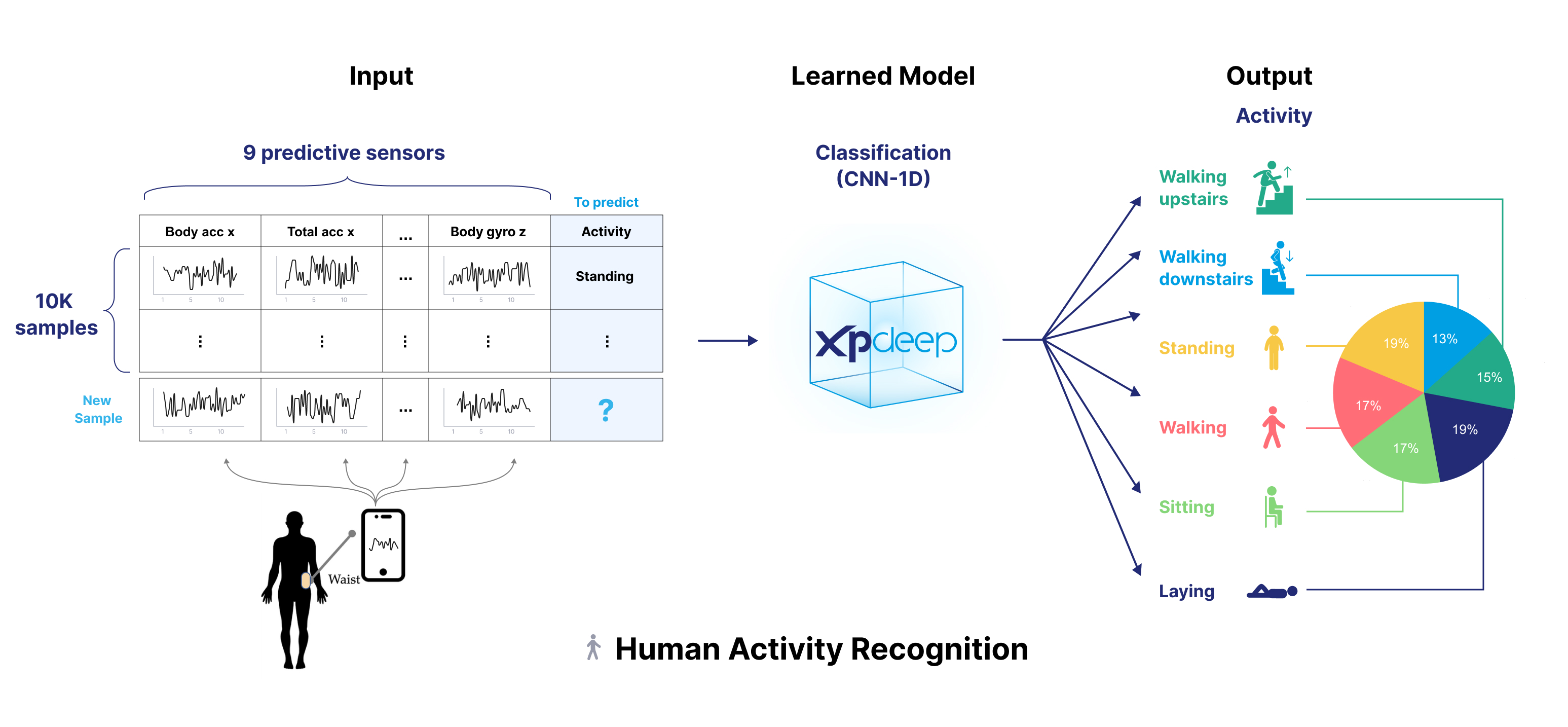
Please follow this end-to-end tutorial to prepare the dataset, create and train the model, and finally compute explanations.
Prepare the Dataset#
1. Split and Convert your Raw Data#
The first step consists in creating your train, test and validation splits as StandardDataset.
As we only have a train and test files, we will use 20% of the train split to create a validation split.
Each ".txt" file in "Inertial Signals" folder corresponds to a single input channel, the target being in the "y_test" and "y_train" files.
We extract each feature file by file, as numpy array format, to get input features "human_activity" as a single array
batch_size x num_timestamps x num_channels.
Let's transform the train (and validation) data:
import pandas as pd
import numpy as np
from pathlib import Path
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32))
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32))
We map the target values to their labels and build the training dataframe.
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying"
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets)
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
Warning
We need to convert the multidimensional array "human_activity" to a list of list, as pandas.DataFrame does not handle
this format natively.
We keep the full training split for training and build validation and test sets by splitting the provided test split in half.
from sklearn.model_selection import train_test_split
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32))
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32))
test_targets = targets_mapper(test_targets) # Map targets to their labels.
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
As stated in the doc, Xpdeep requires a ".parquet" file to create the dataset. The original data is stored as a ".txt" file, therefore each split must be converted to a ".parquet" file.
Tip
To get your ".parquet" files, you can easily convert each split from pandas.DataFrame to pyarrow.Table first.
Like pandas.DataFrame, pyarrow.Table does not support multidimensional arrays, please ensure to convert
arrays to lists first.
Warning
Here with set preserve_index to False in order to remove the DataFrame "index" column from the resulting Pyarrow Table.
import pyarrow as pa
import pyarrow.parquet as pq
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
2. Upload your Converted Data#
Warning
Don't forget to set up a Project and initialize the API with your credentials !
from xpdeep import init, set_project
from xpdeep.project import Project
init(api_key="api_key", api_url="api_url")
set_project(Project.create_or_get(name="Har Tutorial"))
With your Project set up, you can upload the converted parquet files into your fsspec compatible storage, here an S3 bucket.
import boto3
from botocore.client import Config
client = boto3.client(
service_name="s3",
endpoint_url=S3_DATASET_ENDPOINT_URL,
aws_access_key_id=S3_DATASET_ACCESS_KEY_ID,
aws_secret_access_key=S3_DATASET_SECRET_ACCESS_KEY,
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", S3_DATASET_BUCKET_NAME, "har/train.parquet")
client.upload_file("val.parquet", S3_DATASET_BUCKET_NAME, "har/val.parquet")
client.upload_file("test.parquet", S3_DATASET_BUCKET_NAME, "har/test.parquet")
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
3. Find a schema#
For HAR, we cannot use the AutoAnalyzer as it does not support time serie feature yet. We need therefore to create an
AnalyzedSchema from scratch. We add a time serie feature
(9 channels, asynchronous), and a categorical feature for the target (the 6 activities to classify).
We reuse the Scaler preprocessor from xpdeep.dataset.preprocessor.zoo.doc to normalize the time series channels
with the training statistics.
import torch
from xpdeep.dataset.preprocessor.preprocessor import TorchPreprocessor
class Scaler(TorchPreprocessor):
"""A scaling preprocessor."""
def __init__(self, input_size: tuple[int, ...], mean: torch.Tensor, scale: torch.Tensor):
super().__init__(input_size=input_size)
self.mean = mean
self.scale = scale
def transform(self, inputs: torch.Tensor) -> torch.Tensor:
"""Transform."""
return (inputs - self.mean) / self.scale
def inverse_transform(self, output: torch.Tensor) -> torch.Tensor:
"""Apply inverse transform."""
return output * self.scale + self.mean
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
Let's now define the AnalyzedSchema.
from xpdeep.dataset.schema import AnalyzedSchema
from sklearn.preprocessing import OneHotEncoder
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
)
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature()
),
IndexMetadata(name="har_index"),
)
print(analyzed_schema)
+------------------------------------------------------------+
| Schema Contents |
+-------------------------------+----------------+-----------+
| Type | Name | Is Target |
+-------------------------------+----------------+-----------+
| MultivariateTimeSeriesFeature | human_activity | ❌ |
| CategoricalFeature | activity | ✅ |
| IndexMetadata | har_index | |
+-------------------------------+----------------+-----------+
Tip
Categories in the CategoricalFeature are automatically inferred with the preprocessor object after the fitting step.
The categorical feature categories attribute is None prior to the fitting step.
Note
Please note that the __har_index__ column is set as a IndexMetadata in the Schema.
Finally, we can create the AnalyzedParquetDataset. Test and Validation datasets will be created later.
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset
# Create a train dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_dataset",
path=f"s3://{S3_DATASET_BUCKET_NAME}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema
)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
Tip
Here we did not build a ParquetDataset first as we create the dataset straight from the existing analyzed schema.
The ParquetDataset interface serves only as an intermediate class, used to obtain an AnalyzedParquetDataset
via the AutoAnalyzer and its analyze method.
5. Fit the schema#
With your AnalyzedSchema ready, you can now fit the schema to fit each feature preprocessor on the train set.
Note
Only the SklearnPreprocessor will be fitted when calling analyzed_train_dataset.fit() as ScaleHARdoes not
required a fitting step.
We use the same FittedSchema to create a FittedParquetDataset corresponding to the validation and test set.
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
fit_test_dataset = FittedParquetDataset(
name="har_test_dataset",
path=f"s3://{S3_DATASET_BUCKET_NAME}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_dataset",
path=f"s3://{S3_DATASET_BUCKET_NAME}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema
)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
And that's all for the dataset preparation. We now have three FittedParquetDataset, each with its FittedSchema,
ready to be used.
Prepare the Model#
We need now to create an explainable model XpdeepModel.
1. Create the required torch models#
We have a classification task with time serie input data. We will use a basic Multi Layer Perceptron (MLP) and convolutional layers for this task.
Tip
Model input and output sizes (including the batch dimension) can be easily retrieved from the fitted schema.
Therefore, we chose:
- The
FeatureExtractionModelthat will embed input data. - The
TaskLearnerModelthat will return an output of size 6.
Here we define the FeatureExtractionModel and the TaskLearnerModel.
from torch.nn import Sequential
import torch
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(torch.nn.Flatten(), torch.nn.LazyLinear(out_features=6), torch.nn.Softmax(dim=-1))
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
2. Explainable Model Specifications#
Here comes the crucial part: we need to specify model specifications under ModelDecisionGraphParameters
to get the best explanations (Model Decision Graph and Inference Graph).
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
Tip
We use the TEMPORAL_MATRIX feature_extraction_output_type as the output of the feature extraction model is a
temporal matrix (channels-first 1D convolutions).
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
For further details, see docs
Note
All parameters have a default value, you can start by using those default value, then iterate and update the configuration to find suitable explanations.
3. Create the Explainable Model#
Given the model architecture and configuration, we can finally instantiate the explainable model XpdeepModel.
from xpdeep.model.xpdeep_model import XpdeepModel
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
Train#
The train step is straightforward: we need to specify the Trainer parameters.
from functools import partial
import torch
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.trainer import Trainer
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassF1Score, MulticlassConfusionMatrix
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True),
leaf_multi_class_accuracy=TorchLeafMetric(partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True),
global_multi_class_F1_score=TorchGlobalMetric(partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True),
leaf_multi_class_F1_score=TorchLeafMetric(partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True),
global_confusion_matrix=TorchGlobalMetric(partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True),
leaf_confusion_matrix=TorchLeafMetric(partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
trainer = Trainer(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
Warning
Here, we set foreach and fused to False as currently it may leads to unstable behaviour in the training process.
We can now train the model:
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
The training logs are displayed in the console:
Epoch 1/20 - Loss: 1.790: 2%|▏ | 1/46 [00:04<03:22, 4.49s/it]
Epoch 1/20 - Loss: 1.790: 2%|▏ | 1/46 [00:05<03:22, 4.49s/it]
Epoch 1/20 - Loss: 1.576: 4%|▍ | 2/46 [00:06<02:04, 2.83s/it]
Epoch 1/20 - Loss: 1.576: 4%|▍ | 2/46 [00:06<02:04, 2.83s/it]
Once the model trained, it can be used to get explanations.
Explain#
Similarly to the Trainer, explanations are computed with an Explainer interface.
1. Build the Explainer#
We provide the Explainer quality metrics to get insights on the explanation quality. In addition, we compute
along with the explanations histograms to get a detailed distribution on targets and predictions.
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
statistics = DictStats(
distribution_target=DistributionStat(on="target"),
distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
Tip
Here we reuse metrics from the train stage for convenience, but they can be adapted to your needs !
2. Model Functioning Explanations#
Model Functioning Explanations are computed with the global_explain method.
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(model_explanations.visualisation_link)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
We can visualize explanations with XpViz, using the link in model_explanations.visualisation_link, if you already
have requested the correct credentials.
3. Inference and their Causal Explanations#
We need a subset of samples to compute Causal Explanations on. Here we filter the test set to take only the first 100 samples.
from xpdeep.filtering.filter import Filter
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
Future Release
Time serie filters will be implemented to filter based on channel values.
Explanation can then be computed using the local_explain method from the Explainer.
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
👀 Full file preview
"""HAR workflow, classification with time series data."""
import os
from functools import partial
from pathlib import Path
from time import time
import boto3
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from botocore.client import Config
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from torch.nn import Sequential
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchmetrics.classification import MulticlassAccuracy, MulticlassConfusionMatrix, MulticlassF1Score
from xpdeep import init, set_project
from xpdeep.dataset.feature import ExplainableFeature, IndexMetadata
from xpdeep.dataset.feature.feature_types import (
CategoricalFeature,
MultivariateTimeSeriesFeature,
)
from xpdeep.dataset.parquet_dataset import AnalyzedParquetDataset, FittedParquetDataset
from xpdeep.dataset.preprocessor.preprocessor import SklearnPreprocessor
from xpdeep.dataset.preprocessor.zoo.doc import Scaler
from xpdeep.dataset.schema import AnalyzedSchema
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, DistributionStat
from xpdeep.filtering.filter import Filter
from xpdeep.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.feature_extraction_output_type import FeatureExtractionOutputType
from xpdeep.model.model_parameters import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.cross_entropy_loss_from_proba import CrossEntropyLossFromProbabilities
from xpdeep.project import Project, get_project
from xpdeep.trainer.callbacks import EarlyStopping, Scheduler
from xpdeep.trainer.loss import XpdeepLoss
from xpdeep.trainer.trainer import Trainer
STORAGE_OPTIONS = {
"key": os.getenv("S3_DATASET_ACCESS_KEY_ID"),
"secret": os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
"client_kwargs": {
"endpoint_url": os.getenv("S3_DATASET_ENDPOINT_URL"),
},
"s3_additional_kwargs": {"addressing_style": "path"},
}
def main():
"""Process the dataset, train, and explain the model."""
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Read train data
features_dict = {}
split_name = "train"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
train_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
train_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Read test data
features_dict = {}
split_name = "test"
for feature_filepath in sorted(Path(f"{split_name}/Inertial Signals/").rglob("*.txt")):
feature_name = feature_filepath.stem
features_dict[feature_name] = np.squeeze(
pd.read_csv(feature_filepath, sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
test_inputs = np.transpose(np.stack(list(features_dict.values()), axis=1), (0, 2, 1))
test_targets = np.squeeze(
pd.read_csv(f"{split_name}/y_{split_name}.txt", sep=r"\s+", header=None).to_numpy(dtype=np.float32)
)
# Map the target to their labels
activity_mapping = {
1: "Walking",
2: "Walking upstairs",
3: "Walking downstairs",
4: "Sitting",
5: "Standing",
6: "Laying",
}
targets_mapper = np.vectorize(lambda x: activity_mapping[x])
train_targets = targets_mapper(train_targets) # Map targets to their labels.
test_targets = targets_mapper(test_targets)
test_val_data = pd.DataFrame.from_dict({"human_activity": test_inputs.tolist(), "activity": test_targets})
train_data = pd.DataFrame.from_dict({"human_activity": train_inputs.tolist(), "activity": train_targets})
test_data, val_data = train_test_split(test_val_data, test_size=0.5, random_state=42)
print(f"Input shape : {np.array(train_data['human_activity'].to_list()).shape}")
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data.reset_index(names="har_index"), preserve_index=False)
val_table = pa.Table.from_pandas(val_data.reset_index(names="har_index"), preserve_index=False)
test_table = pa.Table.from_pandas(test_data.reset_index(names="har_index"), preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
client = boto3.client(
service_name="s3",
endpoint_url=os.getenv("S3_DATASET_ENDPOINT_URL"),
aws_access_key_id=os.getenv("S3_DATASET_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("S3_DATASET_SECRET_ACCESS_KEY"),
config=Config(signature_version="s3v4"),
)
client.upload_file("train.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/train.parquet")
client.upload_file("val.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/val.parquet")
client.upload_file("test.parquet", os.getenv("S3_DATASET_BUCKET_NAME"), "har/test.parquet")
# 4. Find a schema
train_tensor = torch.tensor(train_table.column("human_activity").to_pylist())
mean = train_tensor.mean(dim=(0, 1))
std = train_tensor.std(dim=(0, 1))
preprocessor = Scaler(input_size=(128, 9), mean=mean, scale=std)
analyzed_schema = AnalyzedSchema(
ExplainableFeature(
name="human_activity",
preprocessor=preprocessor,
feature_type=MultivariateTimeSeriesFeature(
asynchronous=True,
channel_names=[
"body_acc_x",
"body_acc_y",
"body_acc_z",
"body_gyro_x",
"body_gyro_y",
"body_gyro_z",
"total_acc_x",
"total_acc_y",
"total_acc_z",
],
),
),
ExplainableFeature(
is_target=True,
name="activity",
preprocessor=SklearnPreprocessor(preprocess_function=OneHotEncoder(sparse_output=False)),
feature_type=CategoricalFeature(),
),
IndexMetadata(name="har_index"),
)
# Create a dataset from the analyzed schema.
analyzed_train_dataset = AnalyzedParquetDataset(
name="har_train_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/train.parquet",
storage_options=STORAGE_OPTIONS,
analyzed_schema=analyzed_schema,
)
print(analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
name="har_test_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/test.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
name="har_validation_set",
path=f"s3://{os.getenv('S3_DATASET_BUCKET_NAME')}/har/val.parquet",
storage_options=STORAGE_OPTIONS,
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1:]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
class FeatureExtractor(Sequential):
def __init__(self):
layers = [
torch.nn.Conv1d(9, 16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1),
]
super().__init__(*layers)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
x = inputs.transpose(1, 2)
return super().forward(x)
feature_extractor = FeatureExtractor()
task_learner = Sequential(
torch.nn.Flatten(),
torch.nn.LazyLinear(out_features=6),
torch.nn.Softmax(dim=-1),
)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
feature_extraction_output_type=FeatureExtractionOutputType.TEMPORAL_MATRIX,
balancing_weight=0.1,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
example_dataset=fit_train_dataset,
feature_extraction=feature_extractor,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
global_multi_class_accuracy=TorchGlobalMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
leaf_multi_class_accuracy=TorchLeafMetric(
partial(MulticlassAccuracy, num_classes=target_size, average="micro"), target_as_indexes=True
),
global_multi_class_F1_score=TorchGlobalMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
leaf_multi_class_F1_score=TorchLeafMetric(
partial(MulticlassF1Score, num_classes=target_size, average="macro"), target_as_indexes=True
),
global_confusion_matrix=TorchGlobalMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
leaf_confusion_matrix=TorchLeafMetric(
partial(MulticlassConfusionMatrix, num_classes=target_size, normalize="all"), target_as_indexes=True
),
)
callbacks = [
EarlyStopping(monitoring_metric="Total loss", mode="minimize", patience=15),
Scheduler(
pre_scheduler=partial(ReduceLROnPlateau, patience=10, mode="min"),
step_method="epoch",
monitoring_metric="Total loss",
),
]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001, foreach=False, fused=False)
loss = XpdeepLoss.from_torch(
loss=CrossEntropyLossFromProbabilities(reduction="none"),
model=xpdeep_model,
fitted_schema=fit_train_dataset.fitted_schema,
)
trainer = Trainer(
loss=loss,
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
start_time = time()
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
print(f"\nTraining time: {time() - start_time:.2f} seconds\n")
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
distribution_target=DistributionStat(on="target"), distribution_prediction=DistributionStat(on="prediction")
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(quality_metrics=quality_metrics, metrics=metrics, statistics=statistics)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
print(f"\nExplanation time: {time() - start_time:.2f} seconds\n")
print(model_explanations.visualisation_link)
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset, row_indexes=list(range(100)))
causal_explanations = explainer.local_explain(trained_model, fit_train_dataset, my_filter)
print(causal_explanations.visualisation_link)
if __name__ == "__main__":
init(api_key=os.getenv("API_KEY"), api_url=os.getenv("API_URL"))
set_project(Project.create_or_get(name="Har Tutorial"))
try:
main()
finally:
get_project().delete()
We can again visualize causal explanations using the visualisation_link.